
In a previous article, we showed how to improve performance for Nuxeo page providers that have a lot of aggregates. This solution made it so that these aggregates only loaded upon click. The drawback of this solution was the complexity – it involves the creation of multiple page providers and adding aggregates in the form of predicates. This means that, if we want to add a new column in WebUI to query a new aggregate, we must add the new aggregate into previous page providers in form of predicate in order to keep the relationship in the query’s parameters.
As a result, this creates additional work and adds a learning curve to a developer who is new to this customization and who wants to make a simple change. In order to improve maintainability, the following solution can be used to achieve the same impact in a way that makes it easier to add new aggregates.
The basic idea
We want a solution in which there is only a main page provider which has no aggregates that load upon initial page load (or at least very few of these standard types of aggregates). Instead, when users select a filter, we would like Nuxeo to create a temporary aggregate and inject it into main page provider to query the aggregate dynamically.
In order to implement the solution, we need to know the internal mechanism of the Nuxeo page provider and aggregates.
How we get there
To start with, we take a look at the Nuxeo element nuxeo-page-provider, and we find that nuxeo-page-provider retrieves data in two ways. One is to call the REST API by using nuxeo-resource; another way is to call an automation operation through nuxeo-operation. We can find these methods in Nuxeo’s source code. The default way is through using the REST API. Here, for our purposes, we over-ride that default behavior and instead use the automation operation. We just need to create a new operation class and a contribution XML file in the existing module.
Inside nuxeo-page-provider, the default operation is Repository.PageProvider when querying. If we look up PageProvider in Nuxeo’s Documentation, we find that its operation implementation class is org.nuxeo.ecm.automation.core.operations.services.DocumentPageProviderOperation:
If we look at the source code of class DocumentPageProviderOperation and check the method run() and its return type PaginableDocumentModelListImpl, we find that PaginableDocumentModelListImpl class extends PaginablePageProvider class. And in the PaginablePageProvider constructor, pageProvider’s class method, getCurrentPage() was called:
public PaginablePageProvider(PageProvider<T> pageProvider) {
super(pageProvider.getCurrentPage());
this.pageProvider = pageProvider;
}
We need to find the implemented PageProvider class. By unzipping the jar file in Nuxeo Studio package zip file, we can find more details in /OSGI-INF/extensions.xml, and for those page providers that query via Elasticsearch, the class is org.nuxeo.elasticsearch.provider.ElasticSearchNxqlPageProvider.
We also find the page provider defines a search document type whose name is [page provider id] + “_pp”, and the document contains a schema whose name is same as the document type name. Inside the schema, aggregates fields are defined. For example, if the page provider id is “default_search_pp”, its search document type will be “default_search_pp_pp”, and its schema name also will be “default_search_pp_pp”:

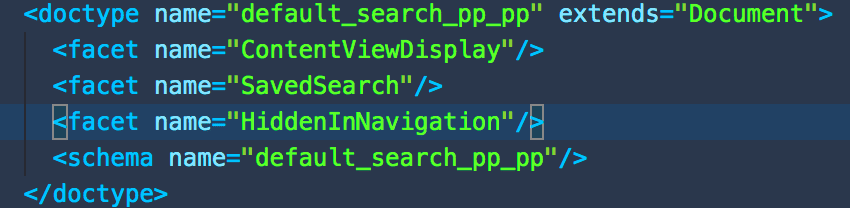

In method getCurrentPage() of class org.nuxeo.elasticsearch.provider.ElasticSearchNxqlPageProvider, before executing the ES query, it will build the ES query and aggregates:
NxQueryBuilder nxQuery = new NxQueryBuilder(getCoreSession()).nxql(query)
.offset((int) getCurrentPageOffset())
.limit(getLimit())
.addAggregates(buildAggregates());
Implementation
Based on the research above, our implementation steps are as follows:
1. Create a customized page provider element “iSS-page-provider” in the Studio element folder based on the Nuxeo element nuxeo-page-provider. In the element, we change the default HTTP method property value to “post” so that it can send a request to the operation using the “nuxeo-operation” instead of using “nuxeo-resource”. We also need to add some parameters that it needs to send to the operation. Finally, we set the operation to our customized operation “ISS.PageProvider”. We will implement it later:
target.op = ‘ISS.PageProvider’;
params.providerName = this.provider;
2. Use the Nuxeo CLI to create an operation “ISS.PageProvider”. We can refer to code from class DocumentPageProviderOperation. In the PageProvider interface, its method getCurrentPage() cannot accept parameters, so we need to create a new interface, IPageProvider, that extends PageProvider and adds a new method getCurrentPage(AggregationDefinition aggregate) so that it can accept our injected aggregate.
In the operation “ISS.PageProvider”, before calling IPageProvider implementation class ElasticSearchNxqlPageProvider, we can create our aggregate:
AggregateDefinition aggregate = null;
// if aggregate is not empty, then create extra aggregate
if (StringUtils.isNotEmpty(aggregation)) {
aggregate = createExtraAggregation();
}
private AggregateDefinition createExtraAggregation() {
AggregateDefinition aggregate = new AggregateDescriptor();
aggregate.setId(aggregation); // id same as field
aggregate.setType(“terms”);
aggregate.setDocumentField(field);
PredicateFieldDefinition predicateFieldDefinition = new FieldDescriptor(schema, aggregation);
aggregate.setSearchField(predicateFieldDefinition);
aggregate.setProperty(“order”, “count desc”);
aggregate.setProperty(“size”, “1000”);
return aggregate;
}
3. We need to send the aggregate id or name, aggregate schema, and the schema’s field to create our aggregate. We can even send more parameters to define aggregate type and properties. In here, we create a terms type aggregate and set its properties with some default values.
4. We need to customize the ElasticSearchNxqlPageProvider class because it is the interface IPageProvider’s implementation class. We need to implement the method getCurrentPage(AggregationDefinition aggregate), We can refer to the getCurrentPage() method; changes are as shown below:
NxQueryBuilder nxQuery = new NxQueryBuilder(getCoreSession()).nxql(query)
.offset((int) getCurrentPageOffset())
.limit(getLimit())
.addAggregates(buildAggregates(aggregate));
// if extra aggregate exist, add into list in order to query dynamically
if (extraDef != null) {
AggregateEsBase<? extends Aggregation, ? extends Bucket> aggregate = AggregateFactory.create(extraDef, getSearchDocumentModel());
if (!skip || !aggregate.getSelection().isEmpty()) {
// if we want to skip aggregates but one is selected, it has to be computed to filter the result set
ret.add(AggregateFactory.create(extraDef, getSearchDocumentModel()));
}
}
5. At this point, we have created the customized operation “ISS.PageProvider” and its implementation, so our next step is to use it. In step 3, we see that the injected aggregate needs at least 3 parameters: aggregate name, aggregate schema, and the schema’s field. When creating a page provider using Nuxeo Studio, it will create an aggregate document and aggregate schema. But the schema does not contain fields to create the temporary aggregates that are needed, and the schema’s fields cannot be changed during runtime. So how do we inject the field into the aggregate schema or document?
Thanks to the Facet feature, we can create a new schema that contains the aggregate’s fields and add the Facet to the aggregate’s document so that we can extend document’s fields.
a) Create an extra aggregate schema, containing all the fields that we need:
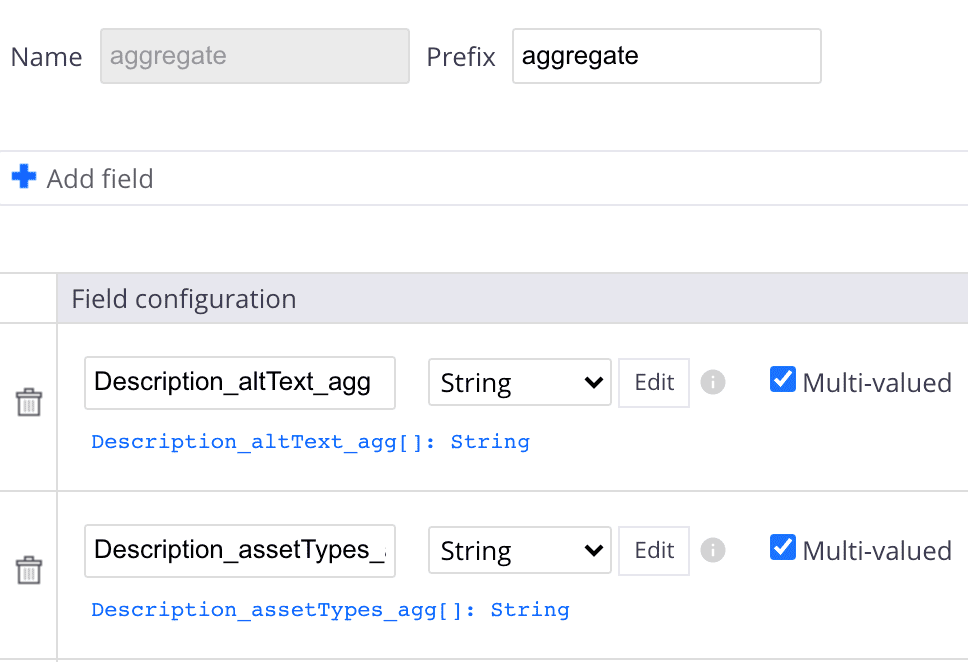
b) Create a document Facet that contains the above schema:
c) Create an extension to append above Facet to page provider’s search document:
<facet name=”Aggregate” />
6. The final step is to modify the UI page to input the aggregate parameters. It will call the customized operation to get the needed aggregates.
Want more information?
Ready to start your Nuxeo journey? Or are you interested in learning about how iSoftStone can help you implement Nuxeo for your critical business needs? Please reach out!



